Many artificial intelligence systems try to understand human emotions by reading facial expressions. However, in practical situations, faces are often captured in poor quality – for example, from CCTV cameras, mobile cameras, video calls, or distant surveillance footage. When such blurred or low-resolution faces are enlarged using ordinary image-enhancement methods, the face may look sharper, but the expression can change. A smile may look less natural, eye details may be altered, or the emotional signal may become unclear.
Many artificial intelligence systems try to understand human emotions by reading facial expressions. However, in practical situations, faces are often captured in poor quality – for example, from CCTV cameras, mobile cameras, video calls, or distant surveillance footage. When such blurred or low-resolution faces are enlarged using ordinary image-enhancement methods, the face may look sharper, but the expression can change. A smile may look less natural, eye details may be altered, or the emotional signal may become unclear.
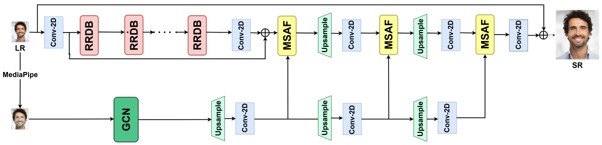
AffectSRNet, created by Dr Syed Sameen Ahmad Rizvi, Assistant Professor, Department of Computer Science and Engineering, SRM AP addresses this problem by enhancing facial images in a way that respects the emotional structure of the face. His research has been published in the Q1 journal of Cognitive Computation, having an impact score of 4.3, under the title “AffectSRNet : Facial Emotion-Aware Super-Resolution Network”. Instead of only making the image visually sharper, the model also considers important facial landmarks such as the eyes, eyebrows, cheeks, lips, and mouth region. These points are treated as a connected facial structure so that the system can better preserve the expression while improving resolution. In simple terms, the model does not merely ask, ‘How can this face be made clearer?’ It also asks, ‘How can this face be made clearer without changing the emotion it is expressing?’
Abstract
Facial Expression Recognition (FER) systems often perform unreliably when the input face images are of low resolution, as commonly encountered in surveillance footage, online communication, mobile imaging, and other real-world visual environments. Conventional face super-resolution methods can improve image clarity, but they may unintentionally distort subtle expression cues such as eye movement, lip curvature, cheek structure, and other facial details that carry emotional meaning. This research introduces AffectSRNet, an emotion-aware face super-resolution framework designed to enhance low-resolution facial images while preserving the fidelity and intensity of facial expressions. The proposed approach integrates facial landmark geometry through Graph Convolutional Networks and combines these structural embeddings with a super-resolution backbone using multimodal attention-based fusion. In addition, the work introduces an Emotion Consistency Metric to evaluate whether the emotional content of a face remains stable after super-resolution. Experiments on standard facial datasets, including CelebA, FFHQ, and Helen, demonstrate that AffectSRNet achieves competitive visual reconstruction quality while improving emotion preservation in comparison with existing super-resolution approaches. The study contributes toward more reliable FER systems for real-world, low-resolution settings.

Practical Implementation and Social Implications
The practical value of AffectSRNet lies in its ability to support emotion-sensitive computer vision applications under low-resolution conditions. It can be integrated as a pre-processing or enhancement module before facial expression recognition systems, particularly where visual quality is limited but emotional interpretation remains important.
- Surveillance and public safety: The framework can improve the reliability of expression-aware analysis in low-resolution video streams, while reducing the risk that enhancement changes the emotional content of a face.
- Human-computer interaction: Emotion-aware interfaces, digital assistants, and affective computing systems can become more responsive when facial expressions are preserved more accurately.
- Online education and remote communication: In low-bandwidth settings, the method can help retain facial cues that are important for engagement, attentiveness, and interaction quality.
- Healthcare and assistive technologies: Emotion-aware visual systems may support patient monitoring, telemedicine, elder-care technologies, and assistive communication tools where facial affect is an important signal.
- Responsible AI development: By emphasizing expression preservation rather than mere visual sharpening, the work encourages more trustworthy, context-sensitive, and human-centered computer vision systems.
At the same time, the social implications of this research require careful and responsible deployment. Any use in surveillance or behavioral analysis should respect privacy, consent, fairness, and institutional ethics. The core contribution is not to intensify monitoring, but to make emotion-aware AI systems technically more reliable and less prone to distortion when image quality is poor
Collaborations
This work was carried out through an academic collaboration involving researchers from the Department of Computer Science & Engineering, SRM University-AP, and the Department of Computer Science and Information Systems, Birla Institute of Technology & Science (BITS), Pilani. The author team includes Syed Sameen Ahmad Rizvi, Soham Kumar, Aryan Seth, and Pratik Narang. Syed Sameen Ahmad Rizvi, Soham Kumar, and Aryan Seth contributed equally to the work. The research was supported by grants from Kwikpic AI Solutions.
Future Research Plans
The future direction of this research is to extend AffectSRNet from a strong image-level framework into a more comprehensive, robust, and real-world deployable emotion-preserving visual intelligence system. Key future plans include:
- Developing graph-inpainting mechanisms to handle severe occlusions such as face masks, sunglasses, partial face visibility, or poor camera angles.
- Extending the framework to video sequences using Temporal Graph Convolutional Networks so that emotional consistency can be preserved across frames and visual jitter can be reduced.
- Exploring multimodal fusion by incorporating audio and other contextual cues to improve expression fidelity in complex interactive environments.
- Evaluating the model across broader demographic groups and real-world datasets to assess generalization, fairness, and robustness.
- Investigating lightweight and deployment-friendly variants for edge devices, mobile platforms, and real-time applications.